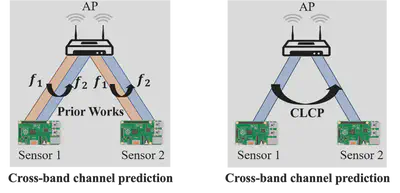
Tomorrow’s massive-scale IoT sensor networks are poised to drive uplink traffic demand, especially in areas of dense deployment. To meet this demand, however, network design- ers leverage tools that often require accurate estimates of Channel State Information (CSI), which incurs a high over- head and thus reduces network throughput. Furthermore, the overhead generally scales with the number of clients, and so is of special concern in such massive IoT sensor networks. While prior work has used transmissions over one frequency band to predict the channel of another frequency band on the same link, this paper takes the next step in the effort to reduce CSI overhead: predict the CSI of a nearby but distinct link. We propose Cross-Link Channel Prediction (CLCP), a technique that leverages multi-view representation learn- ing to predict the channel response of a large number of users, thereby reducing channel estimation overhead further than previously possible. CLCP’s design is highly practical, exploiting existing transmissions rather than dedicated chan- nel sounding or extra pilot signals. We have implemented CLCP for two different Wi-Fi versions, namely 802.11n and 802.11ax, the latter being the leading candidate for future IoT networks. We evaluate CLCP in two large-scale indoor scenarios involving both line-of-sight and non-line-of-sight transmissions with up to 144 different 802.11ax users. More- over, we measure its performance with four different channel bandwidths, from 20 MHz up to 160 MHz. Our results show that CLCP provides a 2× throughput gain over baseline and a 30% throughput gain over existing prediction algorithms.
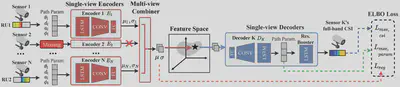
The CLCP framework is shown below:
Our CLCP ML model takes 𝑁 measured channels, each represented as a set of wireless path parameters with L paths estimated from measured channels. Each set of the parameters is served by a Single-view Encoder network E that compresses the measured wireless path information of its dedicated radio and outputs variational parameters. The Multi-view Combiner integrates all variational parameters into 𝜇 and 𝜎, based on which Single-view Decoder networks D generate a set of path parameters that are unobserved. If any input channel is not observed, CLCP drops the respective encoder network (E2, for example)